Apache Spark
Smart Guider — Smart IT Projects

Distributed System — Introduction
- A distributed system is a collection of autonomous computers (separate and independent software or hardware components call nodes) linked by computer networks and equipped with distributed system software to communicate and coordinate their actions only by passing messages.
- They may be on separate continents, counties, in the same building, or in the room.
- The node of the system could be structured or unstructured depending on system requirements.
- Complexity of the system remains hidden to the end-user (human being or computer ). So, End-user can only appear as a single computer.
- It just a bunch of independent computers that cooperate to solve a problem together.
Apache Spark — Introduction

- Apache Spark is an open-source and a cluster-computing framework for data streaming.
- It also design for fast computation. Because, most of the Hadoop applications take more than 90% of the time for read-write operations in HDFS. Thus, A specialized framework was developed by researchers called Apache Spark.
- It enables batch, real-time, and advanced analytics on the Apache Hadoop platform. Because, Apache spark support for in-memory processing computation. That means, It can share objects between jobs, as well as, It can store the state of memory as an object among the jobs.
- And also, It provides high-level APIs in Java, Python, and R, and an optimized engine that supports general computation graphs for data analysis.
- We can show Apache Spark Eco-System compose various components as bellow.
Spark SQL => (SQL and Data-frames) It used to leverage declarative queries and optimize storage executing like SQL queries on Data that are present on RDD and other external sources (structured and semi-structured data).
MLlib => (machine learning) It easy to develop and deploy for scalable machine learning pipelines, some statistics cluster analysis methods, core relations. featured extractions, and any more.
GraphX => (graph processing) It lets data scientistic for working graph and non-graph sources to achieve flexibility and resilience in graph constructions and transformations.
Spark Streaming => (stream processing) It allows to perform batch processing, and streaming of the data on the same application. It also enables high-throughput and fault-tolerant stream processing of live data streams.
Spark R => It provides light-weight front-end, distributed data Flemming implementations that support operations and selections, filtering, aggregations for large data-sets.
- Apache Spark is base on Hadoop Map Reduce and it also extends the Map-Reduce model to efficiently use it for more types of computations, including interactive queries and stream processing.
Features of Apache Spark
- Speed -
In memory => faster up to 100 times, store the intermediate processing data.
On-disk => faster up to 10 times, reduce the number of read/write operations
2. Advanced Analytics
3. Real-time — It offers Real-time computation & low latency because of in-memory computation.
4. Development — support well-defined user API, return Java, Python, Scala, and R, it can be easily deployed in various platform.
5. Powerful caching
Apache Spark Use Cases
It is used for streaming data processing, machine learning, and interactive SQL.
Discuss how that technology preserve following features
- Fault-Tolerant -
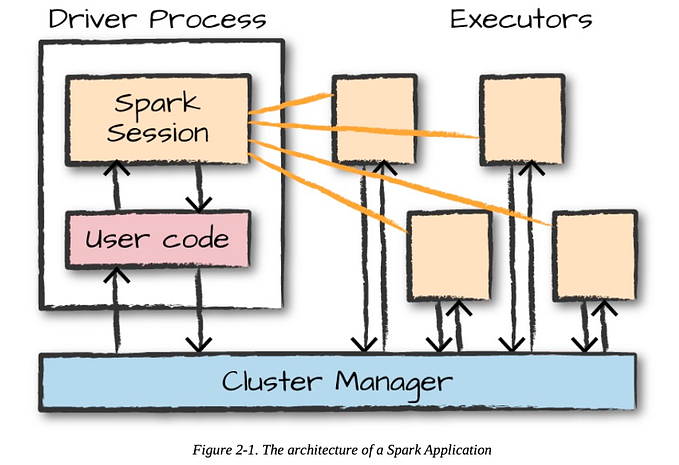
- When consider, one of the abstractions of Apache Spark Architecture is RDD (Resilient Distributed Dataset).
- It is highly resilient. That means, RDD can able to recover fastly from any type of errors, and issues. Because of that, They replicate the same data chunks across multiple executor nodes.
- Therefore, If anyone executor node fails, another executor node can continue the process with data.
2. Highly Available -
- Apache Spark store intermediate results in a Distributed Memory without using Stable storage like Disk. Thus, It makes more faster on the system. Then It can prevent web traffic easily.
- Another thing is if come different queries for the same set of data repeatedly, then It keeps that particular data in distributed memory for making the system faster.
- It gives a real-time computation & low latency because of in-memory computation.
3. Recoverable -
- A distributed system must be able to restart web application and recover missing or lost data even failure occur. Thus, they need to use checkpointing. In Apache spark, it can store steaming information on the HDFS-based checkpoint directory.
- As well as, It tracks lazy operations that performed on each RDD using a “lineage”. Then, each RDD can be recovered in case of losing data at any time.
4. Consistent -
- Apache Spart gives an interactive shell called Spark Shell. It is a powerful tool for analyzing data.
- RDD abstraction can simplify programming complexity. That means, the way of manipulating data collection in local is similar to Application manipulation with RDDs.
5. Scalable -
- Apache spark is fast for large-scale data processing, as well as it can load data into memory and query repeatedly. Also, It makes a well-suited tool for the iterative process and online.
- In the latter, When doing analytics, we want to spend more cost where the computations than data movement or reading from disk. But, After coming Apache spark, it breaks synchronous data-parallel in the processing system. That means,
- Data parallel aspect => same operations applied to partitions of Spark in parallelly.
- Bulk synchronous aspect => All of the processing in one operation wants to finish before moving the next operations.

- Thus, It allows many stages of processing, complex data re-arrangement among the synchronous stages. So, It tells if data are increasing more time to time, that is no issue. They can scale up any time.
6. Predictable Performance -
- As it support for In-memory data computations, Apache spark gives more optimization for any bottleneck. It use to reduce memory usage by serializing data.
- As well as more factors used for spark optimization. There are eliminate the long-running job process, improve performance time by managing resource well, and corrections of the execution engine. Thus, end-user can predict my result come fastly without bottleneck.
7. Secure -
- Apache Spark supports authentication through a shared secret. Spark authentication is the configuration parameter through which authentication can be configured. This parameter checks whether the protocols are authenticated or not. For that, Sender and receiver should have shared secrete for communication. If protocols are not like the shared secrete, they don’t allow for communication.
- When we use the https/SSL setting or javax servlet filters, the spark can be secured. SSL should be configured at each node component involved in communication.
Now, we see how to create a shared secret.
- It will generate and distribute the shared secret to set up spark authentication for spark on YARN and local deployments.
- They should configure secret on every node for any other spark deployment.
Conclusion
Apache Spark is a lighting and fast cluster computing technology. It is designed for fast computation with better performance. This is a most popular distributed system in these days. As discussed Apache spark consists of all features with Fault-Tolerant, Highly Available, Recoverable, Consistent, Scalable, Predictable Performance, and Secure.
Contact with more details: https://smartitprojects.com